
Introduction to Mexima
Weeks ago, I was working on a miniproject called as Meta – External Index Manager. ( MEXIMA). The project was a follow-up of my work on Database Access Methods: Xtree – multidimension index. In Master thesis, I completed and migrated Xtree into Amos II. As it went well then my Professor hinted me to generalize methods I used for Xtree so they can applied to other indexes. The most concern is the External Index Manager (EXIMA) which can be an external C, Java, Python, or other program managing index information and providing useful search methods on the indexed data. Before, I continue explaining what MEXIMA is all about, I shall say a few words about the nature of this work.
First of all, most of Database are equipped with some well known access methods such as Hash table, Btree, and R-tree . . .( the list might go on). These access methods use their special structures to index data. Hence, they make the access ( search) to the data more efficiently rather than scanning, comparing and matching the entire data space. Therefore, they are sometimes are ambiguously called as index structures. However, these access methods are good for some certain data types but not all. For example, Btree is known efficiently useful to access / index Number data but not for multi dimensional data such as multi media data : pictures, movie, . . In fact, the list of domain specified applications using database can be expanded and the fact is that each domain shall have its own frequently used data type. Consequently , there is a need to extend the old index or to introduce a new kind of index structure to support new data type
Similarly, an index structure is only good for some queries but not for all of them. For instance: database user indexes their data with Btree to take advantages of this structure for querying data in a range. As earlier explained, there will be a necessity to extend the database to meet this demand.
However, most of the database are delivered and distributed as a closed source program. Every time a new demand comes up, database vendor will research for a while and launch a new version of its database.
MEXIMA is introduced as another approach to solve the above question. It allows extending the database in term of indexing structures easily. With a few lines of code, high skilled database users / researches easily connect Amos II to a new index manager either written in C / Java or it can be found as a dll/lib.
Here comes the presentation I gave internally in UDBL last couple weeks ago.
Download from here http://cid-50cdb72b173a026e.office.live.com/embedicon.aspx/.Public/Doc/MExinma_v1.pdf
Architecture
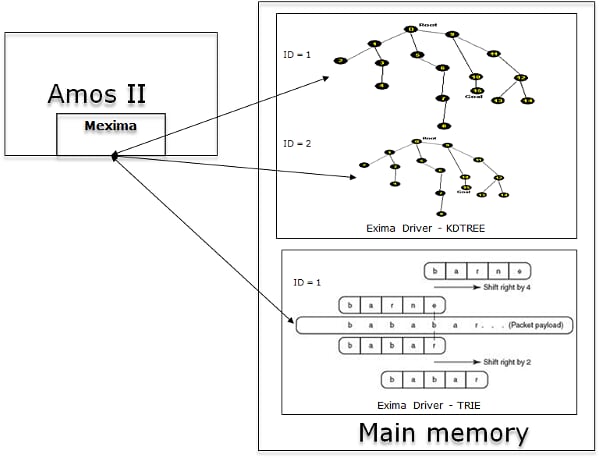
Best practices.
Two in one
PUT = GET + PUT, DELETE = GET + DELETE.
Memory-less MAKE
It should only return a new uniquely generated identifier ( ID) instead of allocating memory for an empty index structure. It is because an index might be created but might not be used meaning it should occupy the minimal memory space.
The PUT
The first PUT is important since it can be a put to allocated index structure or just an empty one. In case, such index could not be found with a given ID. It should be allocated somewhere in the available memory.
Finally, the last assignment of Advance Database course is made of Mexima. You can read the instruction and try the assignment if you wish.